Apache HTTP Server
Collect request rate, worker utilisation, scoreboard state, and traffic metrics from Apache HTTP Server using apache_exporter.
Pattern: apache_exporter → Prometheus scrape → xScaler remote_write
Dashboard
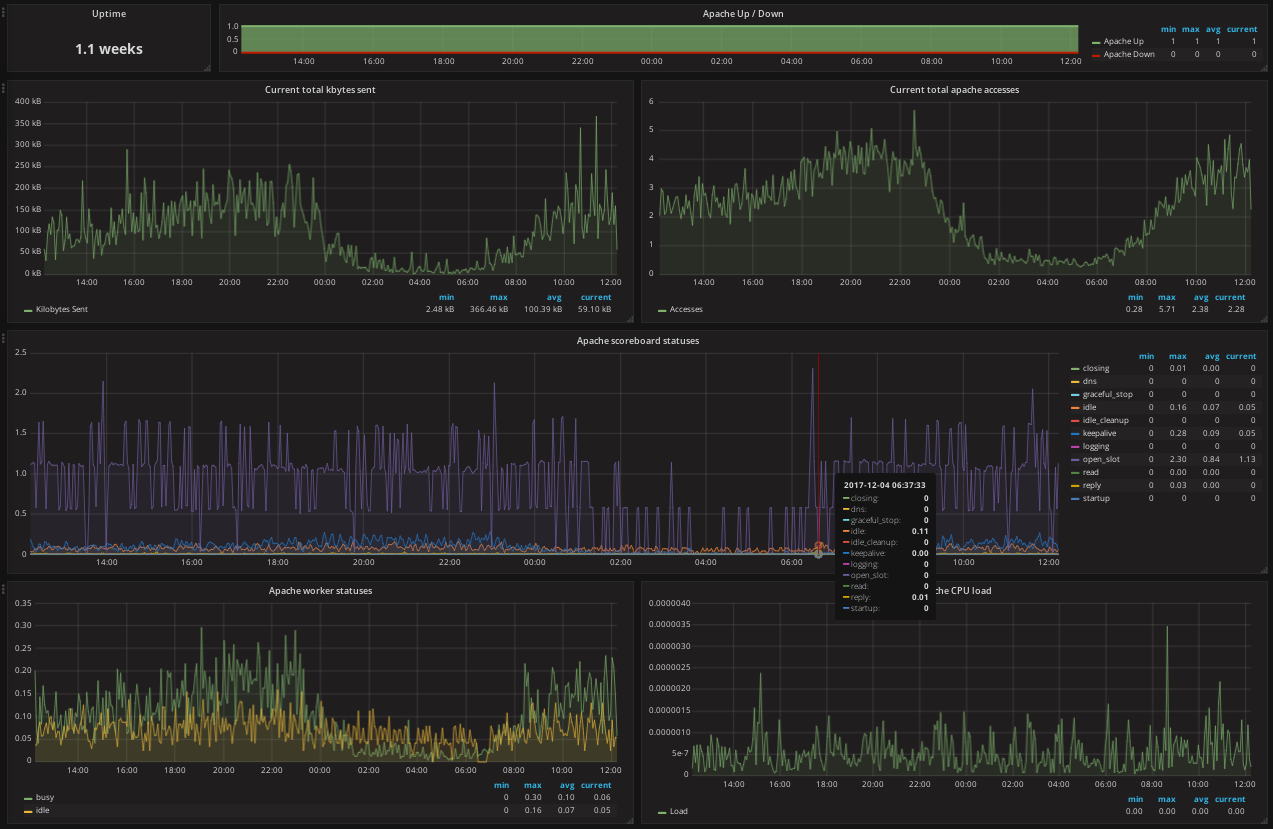
Prerequisites
- Apache HTTP Server 2.4 or later with
mod_statusenabled - Prometheus or Grafana Alloy
- xScaler tenant credentials
Step 1 — Enable mod_status
Add or verify the following in your Apache config (e.g. /etc/apache2/conf-available/status.conf):
<Location "/server-status">
SetHandler server-status
Require local
</Location>
ExtendedStatus On
Enable the config and reload:
# Debian/Ubuntu
a2enmod status
a2enconf status
systemctl reload apache2
# RHEL/CentOS
systemctl reload httpd
Verify:
curl http://localhost/server-status?auto
# Total Accesses: 1234
# Total kBytes: 5678
# ...
Step 2 — Run apache_exporter
docker run --rm -d \
--name apache-exporter \
--network host \
-p 9117:9117 \
lusotycoon/apache-exporter \
--scrape_uri=http://localhost/server-status?auto
Verify:
curl -s http://localhost:9117/metrics | grep apache_up
# apache_up 1
Step 3 — Scrape and forward to xScaler
Prometheus
scrape_configs:
- job_name: apache
static_configs:
- targets: ['localhost:9117']
labels:
instance: web-01
remote_write:
- url: https://euw1-01.m.xscalerlabs.com/api/v1/push
authorization:
credentials: <token>
headers:
X-Scope-OrgID: <tenant-id>
Grafana Alloy
prometheus.scrape "apache" {
targets = [{"__address__" = "localhost:9117"}]
forward_to = [prometheus.remote_write.xscaler.receiver]
}
prometheus.remote_write "xscaler" {
endpoint {
url = "https://euw1-01.m.xscalerlabs.com/api/v1/push"
authorization {
type = "Bearer"
credentials = "<token>"
}
headers = { "X-Scope-OrgID" = "<tenant-id>" }
}
}
OpenTelemetry Collector
receivers:
apache:
endpoint: http://localhost/server-status?auto
collection_interval: 15s
processors:
memory_limiter:
check_interval: 1s
limit_mib: 256
batch:
timeout: 10s
exporters:
otlphttp/xscaler:
endpoint: https://euw1-01.m.xscalerlabs.com
headers:
Authorization: "Bearer <token>"
X-Scope-OrgID: "<tenant-id>"
service:
pipelines:
metrics:
receivers: [apache]
processors: [memory_limiter, batch]
exporters: [otlphttp/xscaler]
Logs
Collect Apache access log and error log. Add the following to your Alloy config:
local.file_match "apache_logs" {
path_targets = [{
__address__ = "localhost",
__path__ = "/var/log/apache2/access.log",
instance = constants.hostname,
job = "integrations/apache_http",
}]
}
loki.source.file "apache_logs" {
targets = local.file_match.apache_logs.targets
forward_to = [loki.write.xscaler.receiver]
}
loki.write "xscaler" {
endpoint {
url = "https://euw1-01.l.xscalerlabs.com/api/v1/push"
http_client_config {
authorization {
type = "Bearer"
credentials = env("XSCALER_TOKEN")
}
}
headers = { "X-Scope-OrgID" = env("XSCALER_TENANT_ID") }
}
}
Key metrics
| Metric | Description |
|---|---|
apache_up | Exporter reachability (1 = up) |
apache_accesses_total | Total number of HTTP accesses |
apache_sent_kilobytes_total | Total kBytes sent |
apache_workers | Worker count by state (busy, idle) |
apache_scoreboard | Scoreboard slot counts by state |
apache_cpuload | CPU load of the Apache process |
apache_uptime_seconds_total | Server uptime |
Useful PromQL queries
# Request rate/sec
rate(apache_accesses_total[5m])
# Busy vs idle workers
apache_workers{state="busy"}
apache_workers{state="idle"}
# Worker utilisation % (busy / total)
apache_workers{state="busy"}
/ (apache_workers{state="busy"} + apache_workers{state="idle"}) * 100
# Throughput (KB/s)
rate(apache_sent_kilobytes_total[5m])
# CPU load
apache_cpuload
Troubleshooting
apache_up 0
- Check
mod_statusis enabled:apachectl -M | grep status - Confirm the
server-statuslocation is accessible:curl http://localhost/server-status?auto - Ensure
Require localallows connections from the exporter's IP
All workers appear busy
- Check
apache_scoreboardfor workers inclosingorloggingstate — may indicate slow clients - Review
MaxRequestWorkers/ServerLimitin your Apache config